rpc framework
smf comes with a high level services DSL and code generator based on
Google Flatbuffers for fast
cross language serialization and
seastar
for its networking and thread model.
bottom line up front: per node overhead
Behind the scenes, Flatbuffers is a backing array + a field lookup table. Every
method call gets looked up on a vtable as an offset into the underlying array.
structs and native types (ints, doubles, bools) are inlined.
Flatbuffers offers a C++, C#, C, Go, Java, JavaScript, PHP, and Python
serialization format.
high level design
The high level design for smf is inspired by facebook::wangle and twitter’s finagle libraries which come with a usability improvement over regular RPC - just the method dispatch - by having hooks/callbacks at different stages of the request lifecycle.
schema
There is no change to your existing fb schema. Let’s build a storage service as an example:
The important bit of the schema that is outside of the normal Flatbuffers generated code is the rpc_service part.
rpc_service SmfStorage {
Get(Request):Response;
}
smf’s rpc code generator parses the schema and generates seastar::future< >s. The input to the method Get is Request and the return type is Response.
let’s look at the generated code
The result of the following generated code comes from calling:
smf_gen --filename demo_service.fbs
which is the name of our compiler/code generator. It is heavily inspired by the Flatbuffers c++ code generator, so if you’ve hacked the fbb compiler before, you’ll feel right at home.
but first things first… how do I use it in my code!
Let’s build a fully functioning service that always returns an empty payload:
class storage_service : public smf_gen::demo::SmfStorage {
virtual seastar::future<rpc_typed_envelope<Response>>
Get(rpc_recv_typed_context<Request> &&rec) final
{
rpc_typed_envelope<Response> data;
return make_ready_future<decltype(data)>(std::move(data));
}
};
server side request anatomy
Let’s look at how the table and dynamic method dispatch work. We’ll focus on these 2 methods of the generated server code:
virtual uint32_t service_id() const override final {
return 212494116;
}
virtual std::vector<rpc_service_method_handle>
methods() final {
std::vector<rpc_service_method_handle> handles;
handles.emplace_back(
"Get", 1719559449,
[this](smf::rpc_recv_context c) {
using t = smf::rpc_recv_typed_context<Request>;
auto session_id = c.session();
return Get(t(std::move(c))).then(
[session_id](auto typed_env){
typed_env
.envelope
.letter
.header
.mutate_session(session_id);
return make_ready_future<rpc_envelope>(
typed_env.serialize_data());
});
});
return handles;
}
In particular note these 2 numbers:
.... service_id()...
return 212494116;
... methods() ...
"Get", 1719559449,
In order to save ourselves 1 extra lookup on the hot-path, the service registration and therefore ID of the method on the wire is the XOR of these 2 id’s.
auto fqn = fully_qualified_name;
service_id = hash( fqn(service_name) )
method_id = hash( ∀ fqn(x) in input_args_types,
∀ fqn(x) in output_args_types,
fqn(method_name),
separator = “:”)
rpc_dispatch_id = service_id ^ method_id;
so how do I send requests to the server then?
Glad you asked! Working backwards from a user’s perspective of how this integrates into your code base:
smf::rpc_typed_envelope<Request> req;
req.data->name = "Hello, smf-world!";
auto client = SmfStorageClient::make_shared("127.0.0.1",2121);
client->Get(req.serialize_data()).then([ ](auto reply) {
std::cout << reply->name() << std::endl;
});
that’s it!
Behind the scenes, the generated code does the glueing of these distinct ids for you.
seastar::future<rpc_recv_typed_context<Response>>
Get(smf::rpc_envelope e) {
e.set_request_id(212494116, 1719559449);
return send<Response>(std::move(e));
}
details about dynamic method dispatch
We want to support this for any number of “services” registered with the
rpc_server that runs these services. To achieve that there has to be someone
responsible for accepting or rejecting the request handles. A
user should be allowed to register an infinite number of services, since the alternative
would be to run in multiple ports. To achieve that, services register
with a router.
class rpc_handle_router {
void register_service(std::unique_ptr<rpc_service> s);
future<rpc_envelope> handle(rpc_recv_context recv);
void register_rpc_service(rpc_service *s);
};
The router is in fact very similar to the current seastar rpc system method function dispatch by id(int). However the main design difference is that we should keep the same id=same_handle even through multiple code generation phases, i.e.: when you extend the schema. To achieve this the register services uses a simple XOR hashing algorithm with fully qualified names, as explained above. Each method has an id + metadata, same with the service.
struct rpc_service {
virtual const char *service_name() const = 0;
virtual uint32_t service_id() const = 0;
virtual std::vector<rpc_service_method_handle> methods() = 0;
};
struct rpc_service_method_handle {
const char *method_name;
const uint32_t method_id;
fn_t apply;
};
// note: this is in fact very similar to how gRPC does it
Given these 2 interfaces, we can come up with a request id.
request_id = service->service_id() ^ method->method_id()
This is how the requests are
tracked. Consistent requests_ids after multiple generations
The last part we have yet to explain is how does request lookup work on
the server side. Assuming a fully parsed request, we have a
request_id that is set by the client, which we generate. The service driver,
aka the rpc_server.h will perform a map lookup of the
request_id == XOR( service_id, method_id )
and determine if we have a function handler for it or not. If we
do, we simply call:
future<rpc_envelope> rpc_handle_router::handle(rpc_recv_context recv);
In practice this lookup never shows up in any perf output - very fast.
filters
template <typename T>
struct rpc_filter {
seastar::future<T> operator()(T t);
};

Earlier we mentioned how smf is inspired by facebook::wangle and by twitter finagle’s rpc systems. In particular the notion of arbitrary filtering is incredibly helpful, if say you wanted to throttle, add telemetry, load shed, etc.
Given our definition of a filter, we can use the same code on both client and server side filtering.
Let’s take a look at a *zstd compression filter:
struct zstd_compression_filter : rpc_filter<rpc_envelope> {
explicit zstd_compression_filter(uint32_t min_size)
: min_compression_size(min_size) {}
seastar::future<rpc_envelope> operator()(rpc_envelope &&e);
const uint32_t min_compression_size;
};
It’s that simple… and using it in your code is even simpler:
// add it to your clients
client->outgoing_filters().push_back(
smf::zstd_compression_filter(1000));
// add it to your servers
using zstd_t = smf::zstd_compression_filter;
return rpc.invoke_on_all(
&smf::rpc_server::register_incoming_filter<zstd_t>, 1000);
SEDA pipelined
What’s more, all your requests are executed in a SEDA pipeline.
static thread_local auto incoming_stage =
seastar::make_execution_stage("smf::incoming",
&rpc_client::apply_incoming_filters);
static thread_local auto outgoing_stage =
seastar::make_execution_stage("smf::outgoing",
&rpc_client::apply_outgoing_filters);
What that means for the user is that they can have many filters and they will execute serially - trading higher throughput for lower latency. In practice filter chains are anywhere from 1-6 and so the impact on throughput is miniscule.
Frame format
/// total = 128bits == 16bytes
MANUALLY_ALIGNED_STRUCT(4) header FLATBUFFERS_FINAL_CLASS {
int8_t compression_;
int8_t bitflags_;
uint16_t session_;
uint32_t size_;
uint32_t checksum_;
uint32_t meta_;
};
STRUCT_END(header, 16);
The frame format is simply a 16 byte header.
This is similar to how the current rpc framework works for seastar,
after frame
negotiation. This fixed format makes it very easy to work with the existing
abstractions of seastar input_stream
Metrics
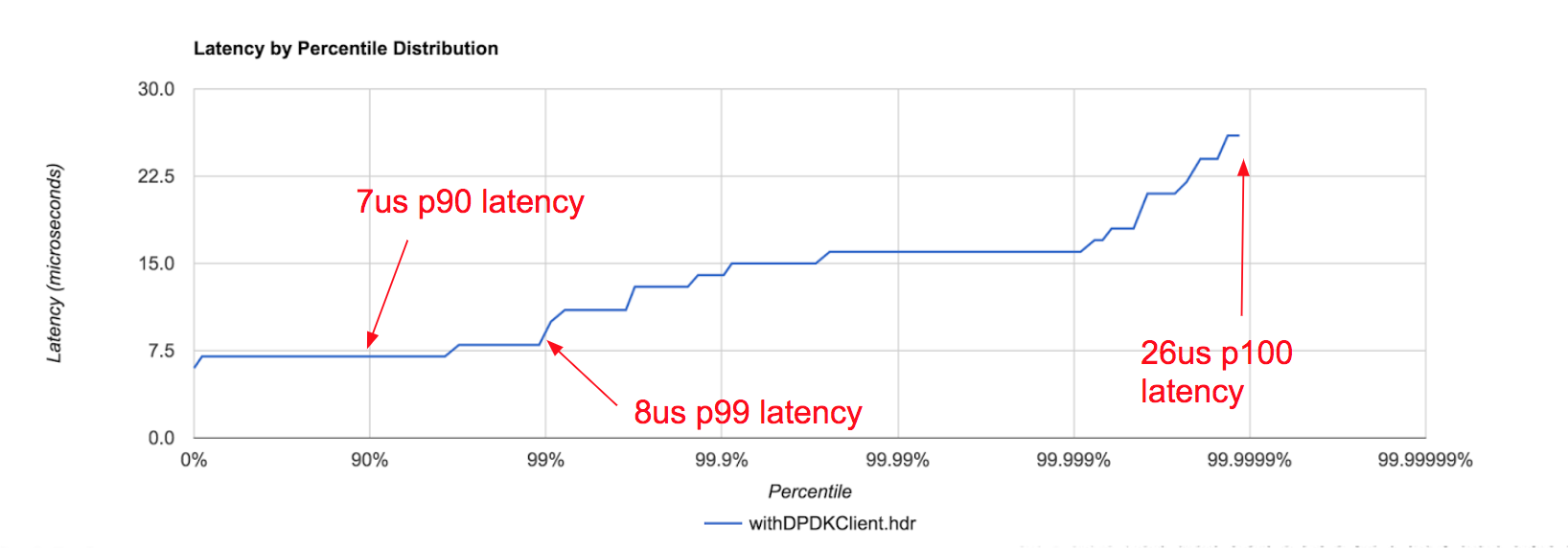
The prototype will also include the famous High Dynamic Range Histogram (HDR Hist) from Gil Tene’s project. Hard-to-track latency tails are already embedded (disabled by default) so you don’t have to manually instrument your code.
Future extensions of the RPC planned to have Google dapper style tracing for RPC calls. However, smf comes with built-in telemetry that is also exposed via the prometheus API. By default we start 2 listening sockets per core. One for telemetry and one for doing actual work. Databases like ScyllaDB use the same strategy.
Similarities with existing rpc
smf very similar to Cap’n Proto - look at the future API used and returned types. However, the networking mechanism used is seastar and the serialization mechanism is Flatbuffers. This project glues them together and enhances them with telemetry, code generation, rpc filter chaining, etc. We leverage the DPDK work that the seastar project built and the fantastic serialization of flatbuffers to build a low latency RPC system.
No serialization. There is no manual or codegen serialization code. The “serialization” is done on the client side, aligning the bytes so that the receiving party doesn’t have to do any work other than a pointer cast to the type:
auto t = (MyType*)payload->mutable_body();
t->name(); // or any other method
Internally this works in a similar way to a std::vector<uint8_t>, where
every time you save a field, it will try to write it, and if it runs out of
space, it will realloc to a new location so that it’s all on a single byte array
before sending to the server.
Let’s look at a wrapper class to handle fully serialized types:
whats next?
Try it!!
Please give us feedback and drop us a line for general discussions, questions, comments, concerns, etc: mailing list